Knowledge Graph Optimization with Schema Markup: The Definitive Guide
❓ What Is Knowledge Graph Optimization with Schema Markup?
Knowledge Graph Optimization with Schema Markup structures web data using JSON-LD vocabularies to build machine-readable entity relationships. This process feeds directly into the Google Knowledge Graph and LLMs, enabling systems like Google SGE and Perplexity to deliver highly accurate, fact-based answers through deep semantic understanding.
Jump to Passage. . .
💡 Unleashing the Business Power of Knowledge Graphs
Enterprise data architecture relies entirely on interconnected entities. Traditional relational databases struggle to map complex relationships at scale, leading organizations to adopt semantic technologies. Knowledge Graph Optimization transforms unstructured web content into a deterministic, queryable format. This structural shift allows search engines and artificial intelligence models to extract exact facts rather than relying on probabilistic keyword matching.
The financial trajectory of this technology highlights its critical role in modern business infrastructure. Industry analysis projects the Knowledge Graph Market to reach USD 6,938.4 million by 2030, growing at a massive 36.6% CAGR from its 2024 valuation of USD 1,068.4 million. This explosive growth stems directly from the need to feed accurate, structured data into enterprise AI systems and search algorithms.
When organizations implement semantic architecture, the operational benefits extend far beyond basic search engine visibility. Connecting disparate data points into a cohesive graph structure allows companies to uncover hidden patterns in customer behavior and operational inefficiencies. For example, businesses utilizing these interconnected semantic networks report a 20% increase in cross-selling efficiency. Furthermore, the average ROI for enterprise graph database projects hits an astonishing 348% over a three-year period.
Nowhere is this impact more visible than in highly regulated industries. The BFSI segment currently dominates the market with a 25.4% share. Banks and financial institutions utilize these systems to map complex transactional relationships, which directly reduces compliance investigation costs by up to 40%. When data relationships are explicit and traceable, auditing becomes a programmatic function rather than a manual investigation.
Leadership teams recognize this fundamental shift in data management. Current metrics show that 92% of IT executives believe these semantic structures drastically improve decision-making speed. By breaking down data silos and linking entities through standardized vocabularies, organizations create a single source of truth that powers both internal analytics and external search visibility.
| Business Metric | Measured Impact | Primary Beneficiary Sector |
|---|---|---|
| Enterprise ROI (3-Year) | 348% Average Increase | Cross-Industry Enterprise |
| Cross-Selling Efficiency | 20% Improvement | Retail & E-commerce |
| Compliance Investigation Costs | 40% Reduction | BFSI (Banking & Finance) |
| Decision-Making Speed | 92% Executive Approval | C-Suite / Operations |
📈 Schema Markup: The Backbone of Search and AI
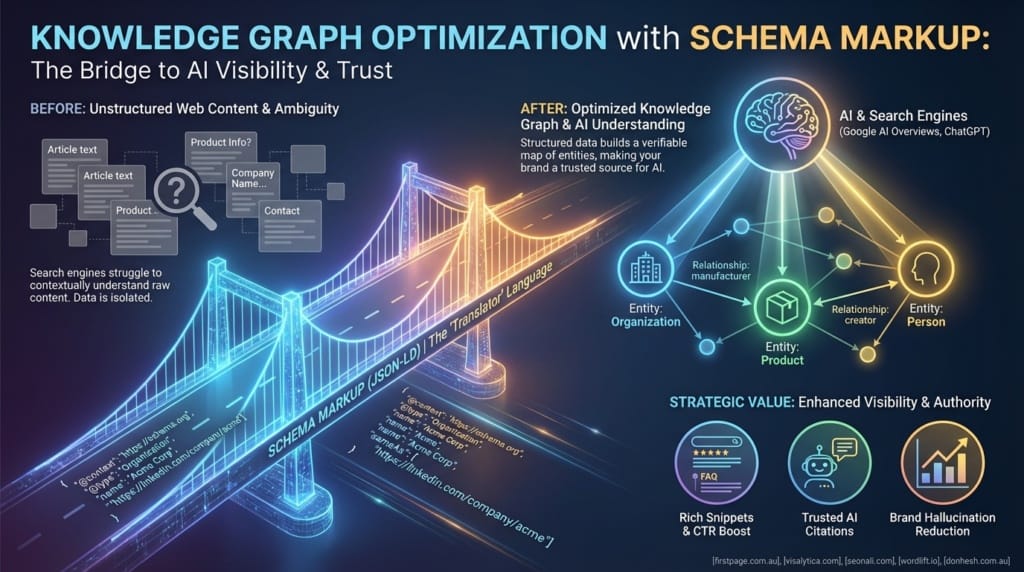
Search engines do not read web pages like humans do. They require structured frameworks to parse entities, attributes, and relationships. Schema Markup provides this exact framework. Launched collaboratively in 2011 by major search engines, Schema.org established a standardized vocabulary that allows webmasters to translate ambiguous HTML text into explicit, machine-readable data nodes.
The evolution of this vocabulary directly parallels the rise of semantic search. The Google Knowledge Graph relies heavily on these structured signals to populate its massive database, which currently houses over 500 billion facts on 5 billion distinct entities. When you implement structured data, you are actively feeding verified nodes into this global ecosystem. This integration is precisely why LLMs grounded in knowledge graphs achieve 300% higher accuracy compared to models relying strictly on unstructured training data.
Technical implementation has also evolved significantly. Early semantic web efforts relied on cumbersome Microdata and RDFa formats, which required developers to interleave vocabulary tags directly within visible HTML elements. This approach proved fragile and difficult to maintain at an enterprise scale. Today, the JSON-LD format stands as the absolute industry standard. JSON-LD allows developers to inject a clean, self-contained script into the page header or body, completely decoupling the semantic data layer from the visual presentation layer.
This decoupling is vital for modern AI visibility. Search generative experiences like Google SGE and AI-driven answer engines like Perplexity utilize JSON-LD to verify facts in real-time. When an AI agent needs to confirm the specifications of a product or the credentials of an author, it bypasses the visual DOM and reads the JSON-LD script directly. Without this semantic layer, your content remains invisible to the deterministic verification processes used by modern AI systems.
Building a robust semantic layer requires specific structural components. You must define the entity type, its unique identifier, and its relationship to other entities on the web. This interconnected web of data is what transforms a simple webpage into a powerful node within the broader semantic web.
- @context: Defines the vocabulary source, almost exclusively set to "https://schema.org" for search engine compatibility.
- @type: Specifies the exact entity class being described, such as "Organization", "Product", or "Article".
- @id: Functions as a unique Uniform Resource Identifier (URI) to merge data about the same entity across different pages.
- mainEntityOfPage: Signals to search engines which specific entity is the primary subject of the current URL.
- sameAs: Links your entity to authoritative external knowledge bases like Wikidata or Wikipedia for definitive disambiguation.
🔍 Real-World Transformations: Case Studies
Theoretical discussions regarding semantic architecture often obscure its practical utility. Examining real-world deployments reveals exactly how organizations leverage Schema Markup to solve complex data fragmentation issues. These case studies demonstrate the versatility of graph-based solutions across entirely different industries and technological requirements.
The National Library Board (NLB) of Singapore faced a monumental challenge regarding data quality and discovery. Their vast archives and library resources existed in isolated, fragmented databases, making cross-referencing nearly impossible for public users. To solve this, the NLB launched a Linked Data-based Semantic Knowledge Graph. By utilizing the BIBFRAME ontology alongside standard Schema.org vocabularies, they successfully merged disparate resources into a unified, searchable network. This implementation allowed users to seamlessly discover related historical documents, author biographies, and publication histories through cross-domain entity linking.
In the environmental sector, HydroKG in Australia tackled a similarly daunting data silo problem. Hydrologic data sources were fundamentally disconnected, impeding critical environmental queries and water management strategies. The organization engineered a solution by merging data from GeoFabric and HydroATLAS into a comprehensive knowledge graph. This semantic integration enabled researchers to execute pinpoint queries on specific rivers, catchments, and water networks. By unifying siloed datasets through explicit graph relationships, HydroKG transformed raw environmental data into actionable ecological insights.
The manufacturing sector also relies heavily on semantic technologies to optimize complex operations. Japanese manufacturing firms historically struggled with inefficient supply chain visibility. Parts, suppliers, and production timelines existed in separate relational tables. By deploying enterprise knowledge graphs, these firms mapped the exact entity relationships within their production ecosystems. This graph structure, supported by internal Schema markup, allowed algorithms to trace supply chain dependencies in real-time, drastically enhancing operational efficiency and bottleneck prediction.
High-volume consumer sectors utilize these same principles for personalization. South Korean Telecom providers faced declining customer satisfaction due to generic, one-size-fits-all service experiences. They integrated knowledge graphs with their customer-facing AI systems to map individual user preferences, device histories, and network usage patterns as interconnected entities. This entity-driven approach fueled highly tailored service recommendations, proving that semantic architecture can operate at consumer scale to directly influence customer retention and satisfaction.
🛠️ Avoiding Mistakes in Schema Implementation
Deploying structured data at scale introduces significant technical risks. Search engines maintain strict guidelines regarding semantic markup, and violations can result in severe visibility penalties. The most critical rule of Knowledge Graph Optimization is maintaining visible content parity. Every single property defined in your JSON-LD script must have a corresponding, visible equivalent rendered on the actual webpage. AI generators frequently hallucinate schema properties that do not exist in the text. When Google detects this mismatch, it flags the site for "Spammy Structured Data", which immediately strips the site of rich results and severely damages its standing in AI Overviews.
Another pervasive failure is shallow entity markup. Many SEO practitioners implement a basic, flat schema. For instance, they might tag a page with a simple "Product" schema and stop there. Modern AI systems require Knowledge Graph depth. A flat product tag provides minimal context. Instead, developers must nest entities to build a comprehensive picture. A proper implementation nests the "Product" within a "Brand", links the "Brand" to an "Organization", and connects the "Organization" to a "Person" (the founder). This deep nesting is what triggers a 25-35% CTR boost in modern search environments, as it provides the exact verification depth AI agents demand.
Disambiguation remains a major stumbling block for enterprise SEO teams. When you mark up an entity, search engines need to know exactly which real-world object you are referencing. Relying solely on internal links for disambiguation provides weak signals. Developers must anchor their entities to authoritative external databases. Skipping Wikidata IDs in the "mentions" or "about" properties is a critical error. By linking your entity to its corresponding Wikidata URI using the "sameAs" property, you provide an undeniable, cryptographic-level verification of the entity's identity.
Finally, the rapid adoption of LLMs for code generation has introduced severe syntax vulnerabilities. Blindly trusting models like Gemini 3 Flash to generate JSON-LD often results in broken syntax, missing commas, or even schema injection attacks. Enterprise teams must never deploy AI-generated schema directly to production. Implementing syntax firewalls, such as Pydantic validators in Python, ensures that the generated JSON-LD strictly adheres to Schema.org specifications before it ever reaches the live DOM.
| Implementation Failure | Negative Impact | Technical Resolution |
|---|---|---|
| Lack of Content Parity | Manual Spam Penalty | Audit JSON-LD against rendered DOM text |
| Shallow Entity Nesting | Exclusion from AI Overviews | Implement multi-layered entity relationships |
| Missing Disambiguation | Weak Entity Authority | Anchor entities using "sameAs" to Wikidata |
| Unvalidated AI Output | Broken Site Syntax | Deploy Pydantic validation firewalls |
🚀 Future Trends: Predictive Roadmap
The intersection of semantic markup and artificial intelligence dictates the future of digital visibility. As large language models become the primary interface for information retrieval, traditional keyword optimization is rapidly losing efficacy. The future belongs to organizations that can feed deterministic, mathematically verified facts directly into AI training pipelines and retrieval systems.
GraphRAG (Graph Retrieval-Augmented Generation) represents the most significant architectural shift in this space. Standard RAG systems rely on vector databases, which retrieve data based on semantic similarity. This often leads to hallucinations because vectors lack explicit relationship understanding. GraphRAG solves this by layering a knowledge graph over the retrieval process. Currently, 45% of AI developers are actively exploring GraphRAG implementations. By utilizing graph databases like Neo4j to map explicit connections, developers ensure that the LLM retrieves not just a semantically similar paragraph, but a mathematically verified relationship between two entities. This specific graph-based data pipeline reduces LLM fine-tuning costs by up to 50% while drastically improving output accuracy.
Entity depth nesting will become the absolute baseline for visibility in 2026 and beyond. AI Overviews and engines like Perplexity do not trust flat data. They operate as fact-verification engines. When an AI agent scans a page, it looks for a cryptographic chain of trust. A product must be linked to a manufacturer, which must be linked to a corporate entity, which must be anchored to a verified Wikidata node. Pages that provide this deep, nested Schema.org v29.x structure are exponentially more likely to be cited as primary sources in AI-generated responses.
Geographically, the Asia Pacific region is leading this enterprise adoption, showing a massive 22.1% CAGR. Driven by complex supply chain logistics and advanced telecom AI requirements, these markets are transitioning into fully graph-native economies. Organizations globally must adapt to this standard. Treating structured data as a mere tactic to acquire star ratings in search results is a fundamental strategic failure. The goal is no longer just rich snippets; the goal is to build a Content Knowledge Graph that directly interfaces with global AI ecosystems.
- Adopt Graph Databases: Transition complex relational data into graph structures using tools like Neo4j to map explicit entity relationships.
- Implement GraphRAG: Upgrade standard vector retrieval systems by layering semantic graphs to eliminate AI hallucinations.
- Deepen Schema Nesting: Move beyond single-layer markup and build multi-tiered entity structures that AI agents can verify.
- Automate with Validation: Utilize LLMs for schema generation at scale, but strictly enforce syntax through programmatic validators.
How Will You Structure Your Semantic Future?
The transition from unstructured text to interconnected semantic data represents the most critical evolution in digital architecture since the invention of the hyperlink. Knowledge Graph Optimization with Schema Markup is no longer an optional SEO enhancement; it is the fundamental language required to communicate with modern artificial intelligence systems.
By implementing deeply nested JSON-LD, anchoring entities to authoritative databases like Wikidata, and leveraging GraphRAG architectures, organizations can transform their static web presence into a dynamic, machine-readable knowledge network. The financial metrics, from massive ROI gains to drastic reductions in compliance costs, clearly validate the necessity of this transition.
The window for gaining a competitive advantage through semantic structure is closing rapidly as AI Overviews become the default search experience. Will your enterprise data remain isolated and invisible to the next generation of AI agents, or will you build the graph that powers their answers?
Knowledge Graph Optimization with Schema Markup FAQs
What is Knowledge Graph Optimization?
It is the strategic process of structuring website data using semantic vocabularies like JSON-LD to help search engines and AI models explicitly understand entity relationships.
How does Schema Markup improve AI visibility?
Schema Markup provides deterministic facts in a machine-readable format. AI engines like Perplexity use this structured data to verify information and confidently cite your content.
What is the difference between Vector RAG and GraphRAG?
Vector RAG retrieves information based on semantic similarity, which can hallucinate. GraphRAG uses explicit entity relationships mapped in a graph database to guarantee factual accuracy.
Why is Wikidata important for Schema Markup?
Wikidata provides a globally recognized, unique identifier for entities. Linking your schema to Wikidata using the sameAs property proves to search engines exactly who or what you are referencing.
Can I use AI to generate my JSON-LD code?
Yes, tools like Gemini 3 Flash can generate markup, but you must use syntax validators like Pydantic to prevent broken code and ensure strict content parity with your visible text.
What happens if my schema doesn't match my page text?
Search engines will flag your site for a Spammy Structured Data violation. This manual penalty removes your rich results and severely damages your visibility in AI-generated answers.
 SEO SOLUTIONS TEXAS BLOG
SEO SOLUTIONS TEXAS BLOG 
We are a results-driven digital marketing and AI SEO agency focused on increasing website traffic, improving online visibility, and generating high-quality leads for our clients.
🏆 Our Services:
Get Access To Our Texan Newsletter
Outrank. Outplay. Outperform.
We deliver elite Texas AI SEO and digital marketing strategies that amplify your presence across search engines, social media, and the platforms that matter most—so you get cited, attract ready-to-buy customers, and turn visibility into unstoppable brand growth.















